The IODA Architecture to me is fundamental. But as many fundamental notions it might be a bit abstract. That’s why I want to provide an example of how to design and implement software based on it. I keep things easy, but not trivial. So here is a scenario:
Build an application that translates a roman number entered by the user into an arabic number and vice versa.
This sounds easy, doesn’t it. It’s more than the code kata Roman Numerals requires, but not much.
Requirements analysis
Before I start with the design, a short analysis seems to be in order.
The requirements ask for an application. That means the user should be able to start a program which converts numbers. But how should the user interact with the program? Since the requirements don’t tell me much about it I assume the simplest approach: a console application. It could work like this:
$ convertroman XIV
14
$ convertroman 42
XLII
$
Roman number conversion is no rocket science. I won’t go into it here. Look it up on Wikipedia, if you like.
What about validation? How should the application react to negative arabic numbers or invalid characters in a roman number? The requirements are silent about this. So I assume just very, very basic validation.
The main purpose of this analysis is clarification of how data gets into the program and how output is presented to the user.
Solution design
The IODA Architecture does not prescribe any behavioral responsibilities. So what can I start with? I could dig into the requirements and identify candidate classes, if I was doing traditional object orientation. But I’m not.
Objects – at least the traditional ones – are secondary. What is primary is behavior. What’s supposed to happen? That’s the driving question.
At the beginning I know very little. I just know, “everything” needs to happen upon a trigger from the user.
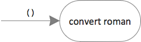
But then, when I think about it, I do know a bit already. It’s just a pattern:
- The input data has to be read. It’s passed in via the command line.
- The data has to be converted.
- The conversion result has to be displayed.
Flow Design
The overall behavior is made up of “parts”; there are distinct processing steps. It can be refined. The current functional unit “convert roman” becomes the root of an integration hierarchy.
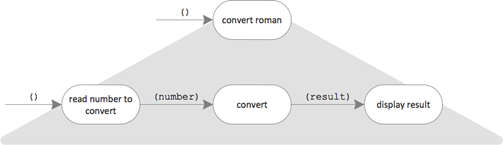
Now I repeat this: For every functional unit I ask myself, from what even smaller processing steps it could be made up of. If I truly understand the problem I’m sure I’ll be able to name at least a few such sub-tasks.
- How complicated is it to read the input number from the command line? It’s trivial. No refinement is needed.
- How much effort is it to display the result? It’s trivial, too. No refinement needed.
- How does the conversion work? That’s not trivial. Refinement seems necessary.
Conversion has at least two sides to it: converting a roman number to its arabic equivalent, and converting an arabic number to its roman equivalent.
Also which conversion to choose needs to be decided.
And how about the simple validation?
Let’s put these behavioral pieces together. Here’s the “domain process” to do the conversion:
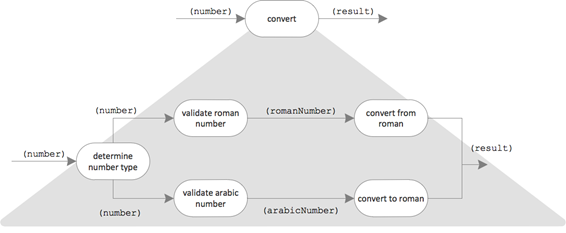
In the former design “convert” was a leaf, an operation. But now it has been opened up and become an integration.
Again I repeat asking myself for every functional unit how difficult it seems to implement it. If I clearly see an implementation before my mental eye, I won’t refine it further during design. Otherwise I need to do a bit more thinking. How could the partial behavior possibly be accomplished as a “domain process”?
To me such a refinement seems to be warranted for both conversions. They are at the heart of the application. That’s really the core domain of the program.
Here is the exemplary decomposition of “convert from roman”: My approach to solve the problem consists of three processing steps.
- Each roman digit of the roman number is translated into its value, e.g. “XVI” -> [10, 5, 1].
- The values are summed to calculate the arabic number, e.g. [10, 5, 1] -> 16.
- In case of a smaller value standing in front of a larger value the smaller value is negated, e.g. [10, 1, 5] -> [10, -1, 5]. I call this “applying the subtraction rule”.
Correctly wired together the “domain process” consisting of these three steps looks like this:
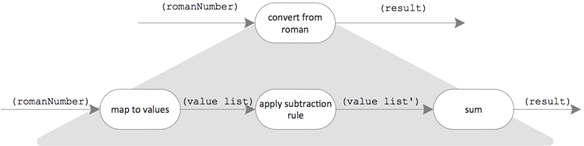
If you, like try the same for the conversion of arabic to roman numbers 😉
Should the new functional units be refined further? I don’t think so. I feel confident to just write down the code. It’s pretty obvious, isn’t it?
So much for the happy day case. But what about a rainy day with invalid input? What to do about it? I think some error output would be nice. I’ll extend the data flows from above like this:
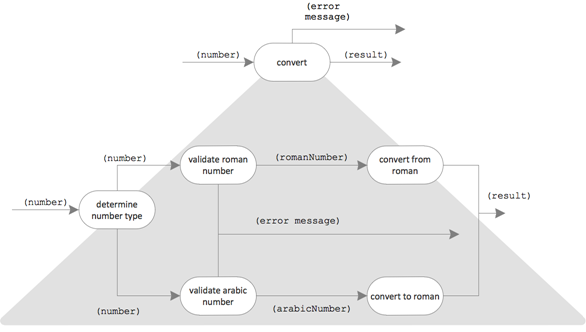
It’s never too late to improve a design 😉
Let’s step back: What is this I’ve designed so far? It’s data flows; I call it Flow Design. It’s a declarative description of what’s supposed to happen to solve a problem (which always is some transformation of input into output and side effects).
At this point I don’t have a clue how the actual logic in each of the operations will look like. That’s the imperative part. It’s implementation details.
But my feeling is ;-), if all operations are implemented correctly, then the integration of them in the depicted manner will lead to a correctly working program.
Here’s the complete final Flow Design for the program with operations marked with dark color:
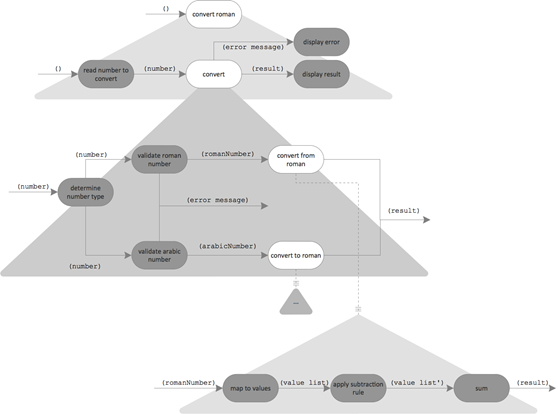
Data Design
So much for the I(ntegration) and O(peration) strata of the IODA Architecture. But what about the D as in Data?
Of course it’s already there. Data is flowing between the operations. Here’s a section of the Flow Design across levels of abstraction with focus on the data:
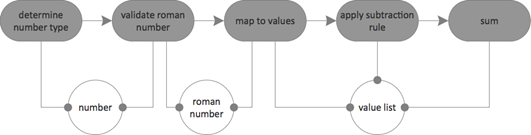
Due to the simplicity of the scenario the data types are all primitive. It’s strings and integers. Maybe, yes, maybe it would be nice to introduce specific types for domain concepts like roman number and arabic number. But right now I don’t see much value in that; it would feel kinda artificial/overengineered. Especially since I’m going to use C# as the implementation language. New types are comparatively expensive using that syntax; I’d be more inclined to define types like that if I was using F#.
Anyway, whether the scenario calls for its own data types or not, this does not change the basic architecture: operations depend/work on data. If there were any specific data structures they’d reside beneath the operation stratum.
Class Design
The “bubbles” you’ve seen so far will be translated to functions in a systematic way. Wait for the implementation…
Functions are modules. And I think each of the bubbles designed so far has a pretty narrow responsibility. It focuses on a single aspect of the requirements. See my article on the Single Responsibility Principle (SRP) for details.
But as important as it is to focus the responsibility of each function (aka bubble), there are more module levels available. I should use them to form higher level responsibilities.
Also, any functions that might be created from the bubbles designed need a class as its home.
Before moving on to the implementation I need some clarity about what classes the program should consist of.
Notice the difference between the usual OOD/P approach. I haven’t thought about classes first, but about behavior/functions. Behavior is primary, classes are secondary.
So I did not have to come up with any “candidate classes”. My classes are the real ones right away. And I know exactly which functions go where. Because I abstract classes from patterns I see in the Flow Design.
Here’s my idea of how to group bubbles into classes:
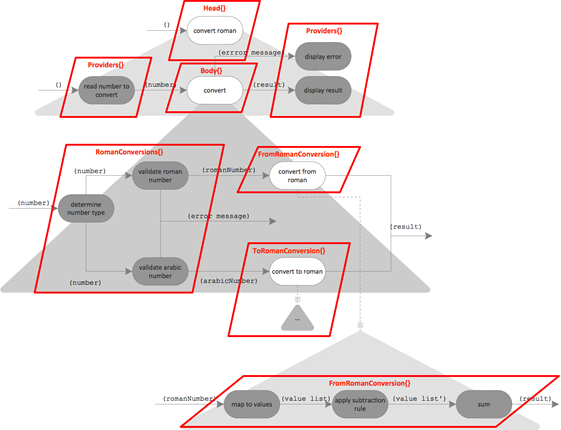
Some of it might be obvious for you, some not. So let me explain my thinking:
- Providers: Using an API is a “hard” aspect in any software. It should be isolated into specific modules. Usually I’d say each API should be encapsulated by its own class – but in this scenario there is so little of it, I guess a single class will do.
- FromRomanConversion and ToRomanConversion: Doing the actual conversion is an aspect of its own. Since there are two directions of conversion a module for each seems to be in order.
- RomanConversions: This class belongs to the coarse grained domain aspect of the application. It contains “helper functions” not actually concerned with the transformations.
- Body: This class represents the overall functionality – but without the interaction with the user. It’s like an internal API to what the program is supposed to do.1
- Head: The head is responsible for triggering body behavior. It integrates the body with input from and output to the user.
Interestingly the class diagram follows the IODA Architecture like the bubbly Flow Design:
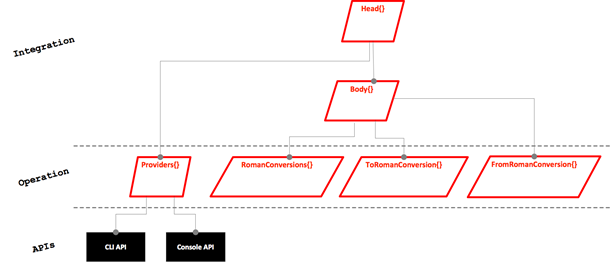
Only the data stratum is missing. But that’s just because the scenario is so simple.
Interfaces and Static Classes
Class design is more than determining which classes there are. It’s also about how the services of those classes should be accessible.
Question #1: Can any classes be static? I’d say that’s a legitimate question; not all classes need to be instantiated. This only makes sense for classes with data or those which should be replaceable or into which replacements (mocks etc.) should be injected.
Looking at the class design for this application I think, RomanConversions, ToRomanConversion, and FromRomanConversion can be static. There is no state involved, no APIs need to be replaced for testing purposes.
This is different for Providers. It encapsulates APIs which might make it hard to test its users like Head. An interface seems in order or maybe even two: one for the CLI part and one for the console output part of the class. Why not apply the Interface Segregation Principle (ISP)?
From that follows Head cannot be made static. It needs to get instances of the provider interfaces injected, since it statically depends on the interfaces and dynamically on some implementation of them.
Also Body should be described by an interface. That would make it easy to test the head in isolation.
Library Design
Aspects are hierarchical so they should be mapped to a hierarchy of modules. Functional units of the Flow Design have been aggregated into classes. But what about the classes?
The next level of modules after classes is libraries. At least in my thinking.
Also libraries are a means of organizing code in many IDEs under the name “project” (eg. Visual Studio) or “module” (eg. IntelliJ).
Again I don’t start with any library candidates, but rather let the classes inspire me. What should be grouped into a library? Here’s my answer:
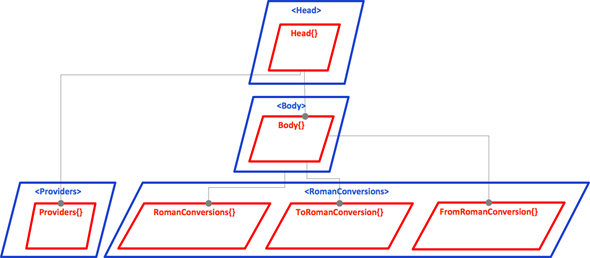
- RomanConversions contains all classes of the business domain.
- Providers is the home for all classes dealing with APIs.
- Head is the top level integrator, the entry point of the application.
- Body does the integration of the “backend”. That’s where behavior is created.
Component Design
The next level in the module hierarchy are components. A component consists of one or more libraries and is described by a separate platform specific contract. This enables a more “industrial” style of software production, since work on different components can be done in parallel, even if they depend on each other at runtime.
The current scenario does not really call for components. I’m working on it alone. But still… I’ll make Providers and Body components, since there are interfaces and possibly several implementations over time. It’s not much effort, so there will be another library for the contracts.
Implementation
Implementing the design is easy. Almost boring 😉 There are clear rules how functional units of Flow Designs should be translated into functions. It took me some 90 minutes to write down the code including all tests.
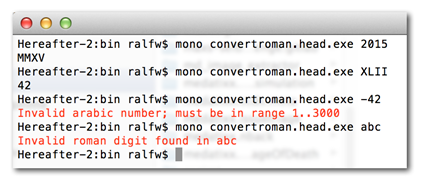
Test-first coding wasn’t necessary since all operation functions are so small. Also the design was already there so I did not need tests to drive it. The tests I set up are there to avoid regressions.
You can view the sources on GitHub.
When looking at the code there should not be any surprises. The project layout follows the component/library design.
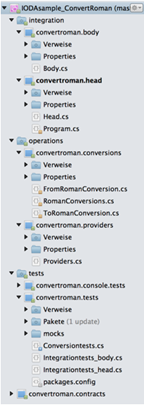
The dependencies between the libraries/classes are as planned.

The code has a IODA architecture on all module levels from functions to components.2
One thing, however, is noteworthy, I guess. How did I translate the bifurcations in the Flow Design, i.e. where the flow splits in two? There are two outputs to “convert”, “determine number type”, and the validations.
When you look at the following code you might need a minute to understand what’s happening:
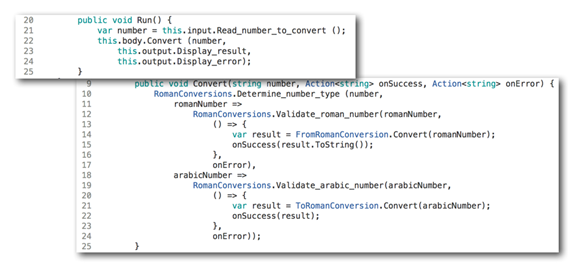
But actually it’s simple. Just read the function calls from top to bottom and left to right. Indentations denote different paths in the flow.
Here’s the topmost flow side by side with its implementation:
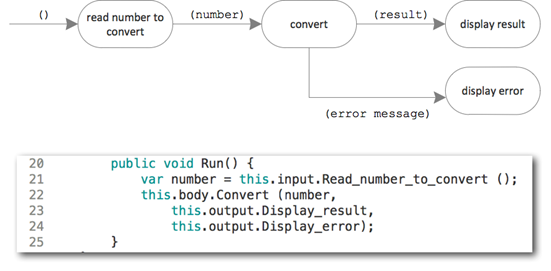
Each bubble translates to a function call. If there is only one output, the function returns a value. If there is more than one output, the function passes on a value using a continuation (function pointer). Those continuations are what makes the code a bit hard to read. But only at first. It’s unusual, not wrong. You just have been trained for so long to read nested function calls from right to left and inside-out; but once you get used to continuations you’ll come to appreciate how easy it is again to read code.
Elements of Functional Programming are used to translate the declarative Flow Design into OO language code.
But that’s only details. My main point was to show you, that designing a IODA Architecture for an application is not difficult. And implementing the design is not difficult either.
The universal aspects of integration, operation, and data (admittedly not much in this case) have been separated. And orthogonal to that behavioral aspects have been identified and encapsulated into modules on different levels.
- This root class could also be called Application or maybe viewed as a use case and named accordingly.↩
- There are slight exceptions. Although the classes FromRomanConversion and ToRomanConversion are operations from the point of view of the class design, they contain both integration functions and operation functions. As long as there is a large imbalance between the two aspects that’s ok. If the number of integration functions would grow in such a hybrid class, though, it would hint at splitting it into dedicated integration and operation classes.↩
Print | posted on Saturday, May 2, 2015 2:19 PM | Filed Under [ Software architecture ]

